Bioinformatics

Wide-ranging expertise in data analysis and visualisation, software development, statistics and experimental design.
The Bioinformatics Core provides support for data analysis, statistics, and software development, working collaboratively with colleagues in CRUK CI and research scientists within the University of Cambridge. We offer advice on experimental design, statistical modelling, and hypothesis testing and run training courses to assist research scientists in performing their own analyses.
The Bioinformatics Core operates on a fee-for-service basis. We are open to working with groups from other universities and research institutes and from within industry. Enquiries can be made by emailing bioinformatics@cruk.cam.ac.uk.

Dr Matthew Eldridge
Focus areas

Bioinformatic analysis
Our team of bioinformaticians has extensive experience in analysing datasets generated by high-throughput technologies and supports research projects that employ a range of experimental techniques, including:
- RNA-seq for differential gene expression between sample groups, e.g., treated vs. untreated cell lines, and single cell RNA-seq for identification and characterisation of sub-populations of cells
- Whole genome, exome, and amplicon sequencing to explore variation in cancer genomes, identifying mutations, copy number aberrations and genomic rearrangements
- Spatial transcriptomics to determine where different genes are expressed in a tissue sample
- Nanopore long-read sequencing
- Quantitative proteomics including tandem mass tag mass spectrometry to detect changes in protein abundance following treatment or a perturbation

Statistical design and analysis
We support a wide range of statistical designs to improve signal-to-noise ratio, reproducibility and external validity of preclinical experiments that aim to advance our understanding of the causes of cancers. We determine appropriate statistical methods and apply these to a wide variety of complex data types. Some examples of the type of work we carry out include:
- Design and analysis of preclinical in vivo experiments, e.g. antitumour activity experiments
- Regression models (e.g. ANOVA, generalized linear models) with fixed and random effects applied to cancer progression and treatment response
- Parametric and distribution-free models for survival analysis
- Rule-based and model-based designs for dose-finding and dose-response studies

Software development
We have developed several software packages for analysing and visualizing the data sets we work with. These include analysis pipelines for processing data at scale, interactive web applications, web services and the relational databases that these access, and bespoke tools written in various programming languages, mainly R, Python and Java.
We also provide expert advice to other groups in the institute on best practices for developing robust software solutions. Many of our software packages and tools are available on GitHub.

Genomic data processing
The Bioinformatics Core is actively involved in processing increasingly large volumes of genomic sequencing data and develops pipelines to run these analyses efficiently on the CRUK CI high-performance compute cluster.
Working closely with the Genomics Core, we play an active role in the smooth running of the genomic sequencing operation and are responsible for developing and maintaining the LIMS deployment and automated workflows for data processing and QC. This includes the large-scale management and delivery of sequence data to hundreds of users.

Training
An important role of the Bioinformatics Core is to provide training to CRUK CI scientists and, working with the University of Cambridge Bioinformatics Training Facility, we offer a range of classroom-based training courses with an emphasis on hands-on, practical-based learning.
We teach courses on experimental design, statistical modelling and analysis, analysis of bulk and single-cell RNA-Seq data, and data science using the R programming language.
More details on our training courses can be found here.
Group Members
-

Matthew Eldridge
Head of Computational Biology
-

Abigail Edwards
Senior Bioinformatics Analyst
-

Ashley Sawle
Principal Bioinformatics Analyst
-

Chandra Chilamakuri
Senior Bioinformatics Analyst
-

Kamal Kishore
Senior Bioinformatics Analyst
-

Luca Porcu
Senior Statistician
-

Richard Bowers
Senior Bioinformatics Developer
Related News
See all news-
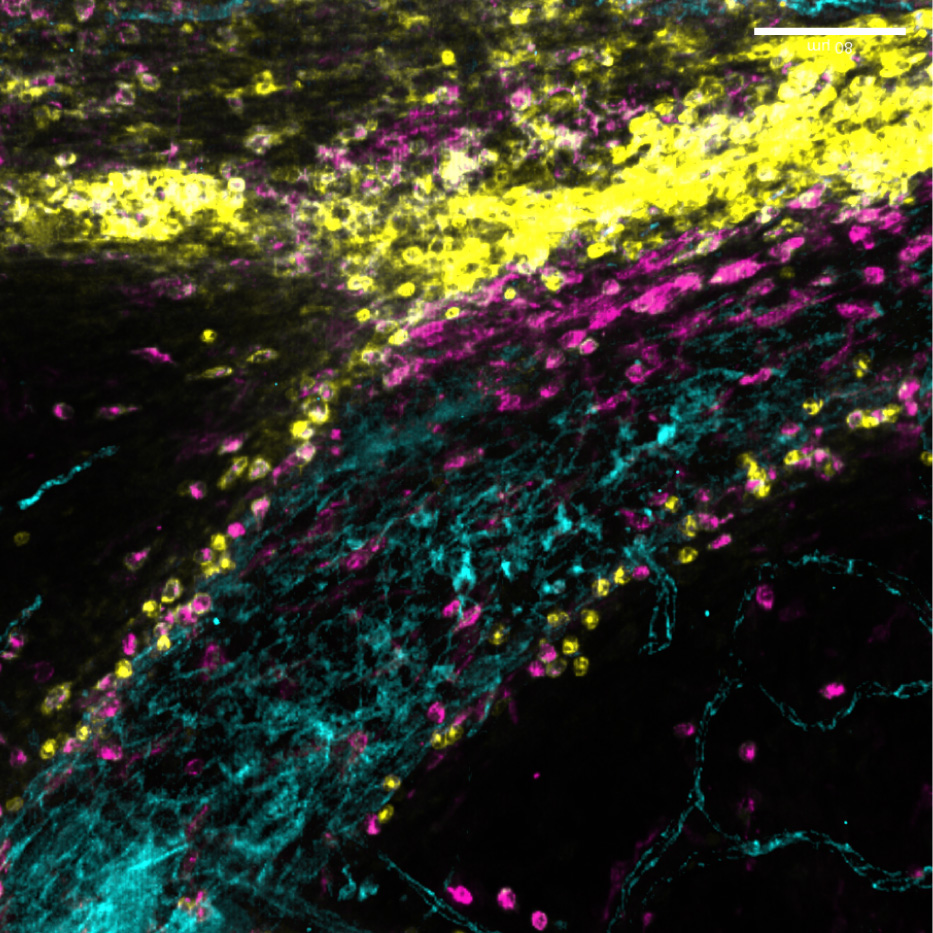
New immune pathway offers treatment hope for childhood brain tumours
3rd February 2026
A newly discovered immune pathway could lead to gentler treatments for multiple childhood brain cancers, according to new research from our Gilbertson Group published today in Nature Genetics.
Find out more -
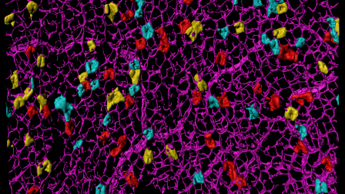
Order of cancer-driving mutations affects the chance of tumour development
3rd December 2025
New research from the Winton Group has revealed that the order of cancer-driving mutations plays an important role in whether tumours in the intestine can develop.
Find out more -

Institute scientists uncover molecular switch that drives pancreatic cancer progression
30th October 2025
New research from our Carroll Group has identified a molecular mechanism that helps explain how pancreatic ductal adenocarcinoma progresses, offering a potential path toward more targeted treatments.
Find out more
Laboratory Efficiency Assessment Framework (LEAF)
Bioinformatics contributed to the Institute’s LEAF Silver accreditation, see the Sustainability webpage for more information.